Parcae: Doing More with Fewer Parameters using Stable Looped Models
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Dan Fu
TL;DR: We present Parcae, one of the first stable architectures for looped language models, achieving the quality of a Transformer twice the size with clean, predictable training. Parcae creates a new medium to scale quality by increasing recurrence rather than purely scaling data, opening up an efficient frontier for training memory-constrained on-device models.
Getting the most out of your parameters.
Traditional scaling laws tell us that to achieve the best performance, we need to scale FLOPs, often with more parameters or data. But as models move to the edge and inference costs skyrocket, we wonder: Can we scale quality without inflating memory footprint?
To that end, we’ve been exploring looped architectures, models that increase compute by passing activations through the same layers multiple times. While promising, these models have been unstable to train. We tackle this issue directly and introduce Parcae, a stable looped architecture that:
- Is better than prior looped models: Parcae achieves up to 6.3% lower validation perplexity than previous large-scale looped recipes.
- Punches above its weight: Our 770M Parcae matches the quality of a 1.3B parameter Transformer trained on the same data, achieving the same performance with roughly half the parameters.
- Scales Predictably: We establish the first scaling laws for looping, finding that compute-optimal training requires increasing looping and data in tandem.
Looped models are cool, but hard to train in practice…
As models move to the edge and inference deployments take on larger portions of compute, there is an increasing interest in scaling model quality without increasing parameters. One mechanism we have been excited about is layer looping, where initial works have trained looped models that match the quality of larger fixed-depth architectures.
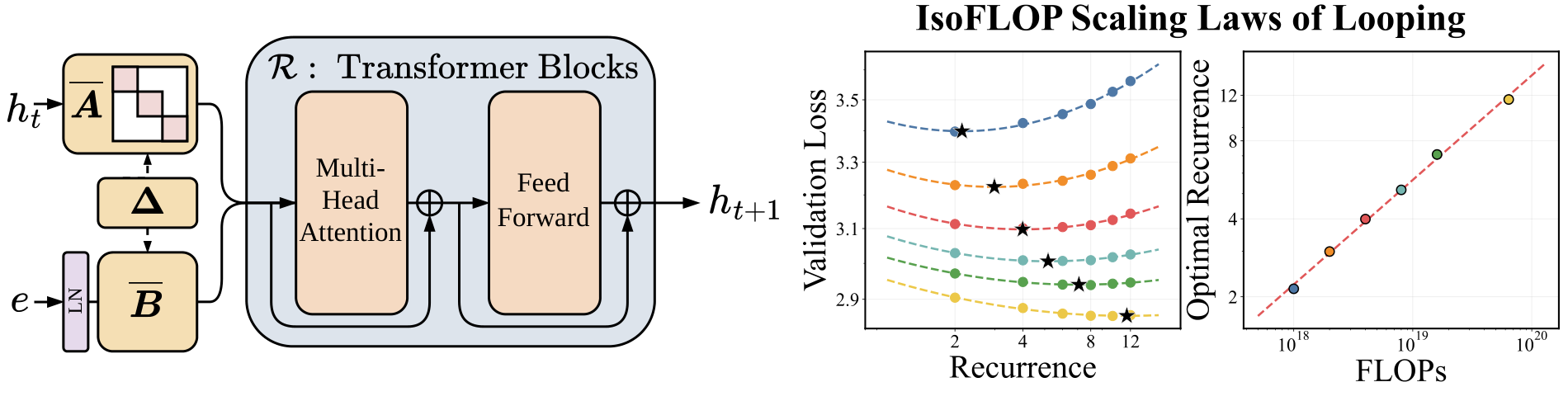
To turn a vanilla Transformer into a looped model, we follow prior work and partition its layers into three functional blocks: a prelude ($\prelude$), a recurrent ($\recurrent$), and a coda ($\coda$). The forward pass works in three stages:
- Embedding: The prelude transforms the input into a latent state $e$.
- Recurrence: The recurrent block iteratively updates a hidden state $h_t$ for $T$ loops. To maintain the input’s influence, $e$ is injected into each loop, typically via addition [1] ($h_{t+1} = \recurrent(h_t + e)$) or concatenation with projection [2] ($h_{t+1} = \recurrent(W[h_t; e])$).
- Output: The coda processes the final $h_T$ to generate the model’s output.

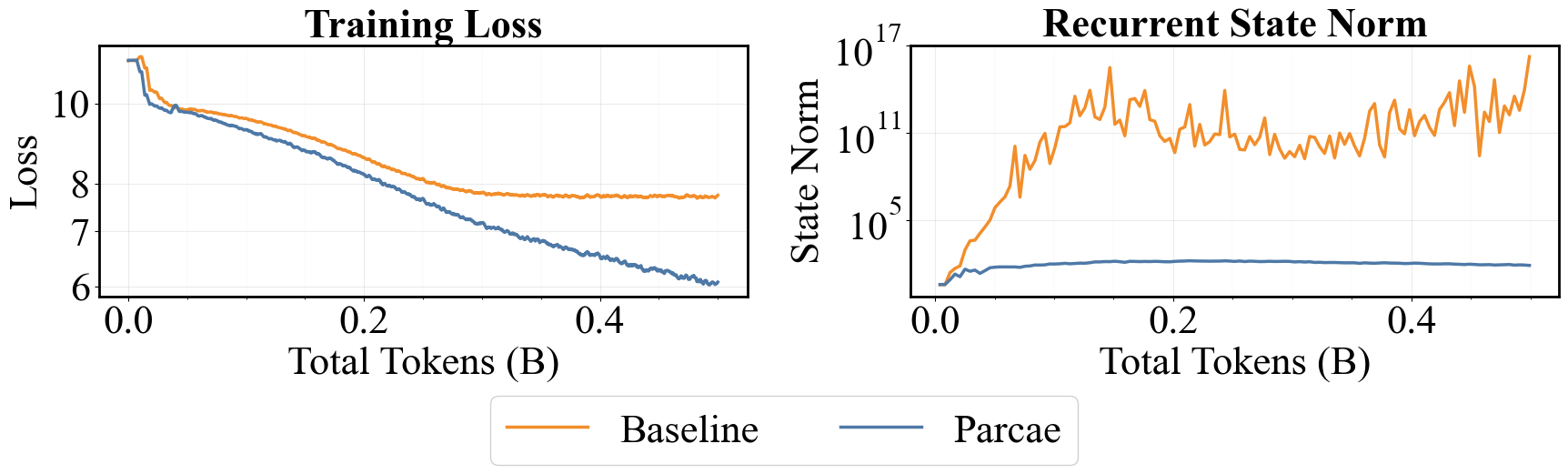
Unfortunately, looped models are a headache to train [2][3][4]. We personally found them to suffer from residual state explosion and loss spikes. What makes looped models even trickier is that the recurrent block is composed of several vanilla Transformer blocks, making it difficult to reason about the source of instability.
Understanding the instability of looping.
While instability is a fickle foe, we observed that a simple linear framework captured a significant source of instability. Specifically, we recast looping as a nonlinear time variant dynamical system over the residual, whose update rule is:
\[h_{t+1} = \dA h_t + \dB e + \overline{\recurrent}(h_t, e)\]where $\dA, \dB$ perform injection and $\overline{\recurrent}$ is the contribution of the Transformer blocks to the residual stream. For the subquadratic sequence mixing fanatics out there, observe that if we ignore the nonlinear term $\overline{\recurrent}$, the resulting system is a discrete linear time-invariant (LTI) dynamical system over the residual state, across model depth.
What’s cool is that for discrete LTI systems, their stability and convergence are determined by the eigenvalues of $\dA$. Specifically, stability is categorized using the spectral norm $\rho(\dA)$ (i.e., the absolute largest eigenvalue of $\dA$), with stable systems (convergent) being $\rho(\dA) < 1$ and unstable (divergent) systems being $\rho(\dA) = 1$.
| LR | Unconstrained $\overline{A}$ | Parcae |
|---|---|---|
| 2e-4 | ✓ | ✓ |
| 4e-4 | ✗ | ✓ |
| 6e-4 | ✗ | ✓ |
| 8e-4 | ✗ | ✓ |
| 1e-3 | ✗ | ✓ |
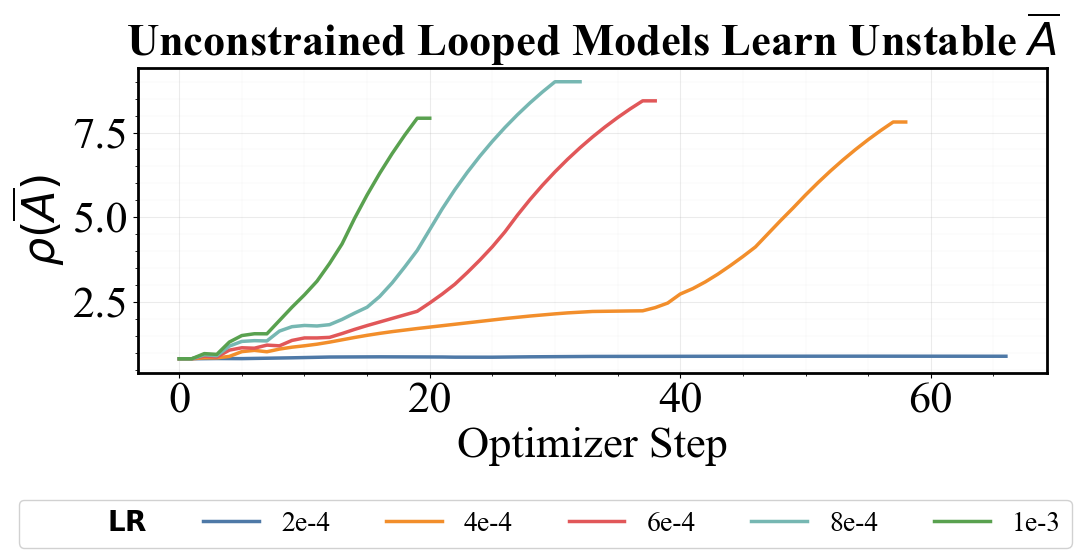
While this analysis bypasses the nonlinearities of looping (e.g., Attention and MLP units), the table and figure above confirm that our analysis is important empirically: divergent runs learn a spectral radius of $\rho(\dA) \geq 1$, with convergent runs maintaining $\rho(\dA) < 1$. When we maintain LTI conditions with Parcae, looped models become significantly more robust to hyperparameter selection.
Parcae: A stable, hassle-free looped model
So how do we stabilize? We designed a new looped model, Parcae, which explicitly maintains the stability conditions observed in the section above by construction. Specifically, we parameterize the input injection parameters using a continuous formulation $\A, \B$, which we discretize with ZOH and Euler schemes (i.e., $\dA = \exp(\dt \A)$ and $\dB = \dt \B$), using a learned $\dt \in \R^{d_h}$. We then constrain $\A := \mathrm{Diag}(-\exp(\mathtt{log_A}))$ as a negative diagonal matrix, where $\mathrm{Diag}(-\exp(\cdot))$ of a vector enforces negativity and $\mathtt{log_A} \in \R^{d_h}$ is our learnable vector. This ensures that $\rho(\dA) < 1$!
So, have we fixed all the issues and stabilized looped models? Unfortunately, there were still several other small tricks needed to get clean training of Parcae. For those interested, check out our paper.
Back to language modeling: Scaling up Parcae
Not only does Parcae train more reliably, but we found that it produces a higher-quality model in comparison to prior RDMs. Using the exact setup of RDMs [2], a prior looped model, we tested against parameter- and data-matched RDMs, observing that Parcae reduces validation perplexity by up to 6.3%.
| Params & Model | Val. PPL (↓) |
|---|---|
| 100M Scale | |
| RDM | 14.23 |
| Parcae | 13.59 |
| 350M Scale | |
| RDM | 10.76 |
| Parcae | 10.09 |
When retrofitting a very strong Transformer baseline into an RDM, without any hyperparameter tuning, we found Parcae to be robust over RDMs (which just flat-out diverged).
| Params & Model | Val. Loss (↓) | Core (↑) | Core-Extended (↑) |
|---|---|---|---|
| RDM | Divergent | Divergent | Divergent |
| + Parcae Constrained A | 2.97 | 13.2 ± 0.2 | 9.1 ± 0.5 |
| + All Parcae Tricks | 2.95 | 14.0 ± 0.2 | 9.7 ± 0.3 |
We also took Parcae and used it as a drop-in replacement for a standard fixed-depth Transformer. Using a nanochat-inspired setup, we train a series of language models on FineWeb-Edu, up to 1.3B parameters. We found that Parcae outperformed all parameter- and data-matched Transformers, with our 770M Parcae model almost achieving downstream quality equivalent to a Transformer twice its size!
| Params & Model | Val. PPL (↓) | Core (↑) | Core-Extended (↑) |
|---|---|---|---|
| 140M Scale | |||
| Transformer | 21.48 | 13.00 ± 0.15 | 8.80 ± 0.21 |
| Parcae | 19.06 | 14.04 ± 0.20 | 9.67 ± 0.28 |
| 370M Scale | |||
| Transformer | 15.79 | 17.46 ± 0.03 | 11.71 ± 0.22 |
| Parcae | 14.49 | 20.00 ± 0.06 | 12.75 ± 0.31 |
| 770M Scale | |||
| Transformer | 13.08 | 22.42 ± 0.20 | 14.20 ± 0.63 |
| Parcae | 12.49 | 25.07 ± 0.33 | 15.19 ± 0.43 |
| 1.3B Scale | |||
| Transformer | 11.95 | 25.45 ± 0.08 | 15.90 ± 0.23 |
| Parcae | 11.42 | 28.44 ± 0.28 | 17.08 ± 0.09 |
To loop, or not to loop
But is looping actually FLOP-efficient? To study this, we explore a setting where, under a fixed parameter count and FLOP budget, we trade off mean recurrence during training against data. That is, if we increase mean recurrence, we reduce the amount of training data so the total FLOP budget stays fixed.
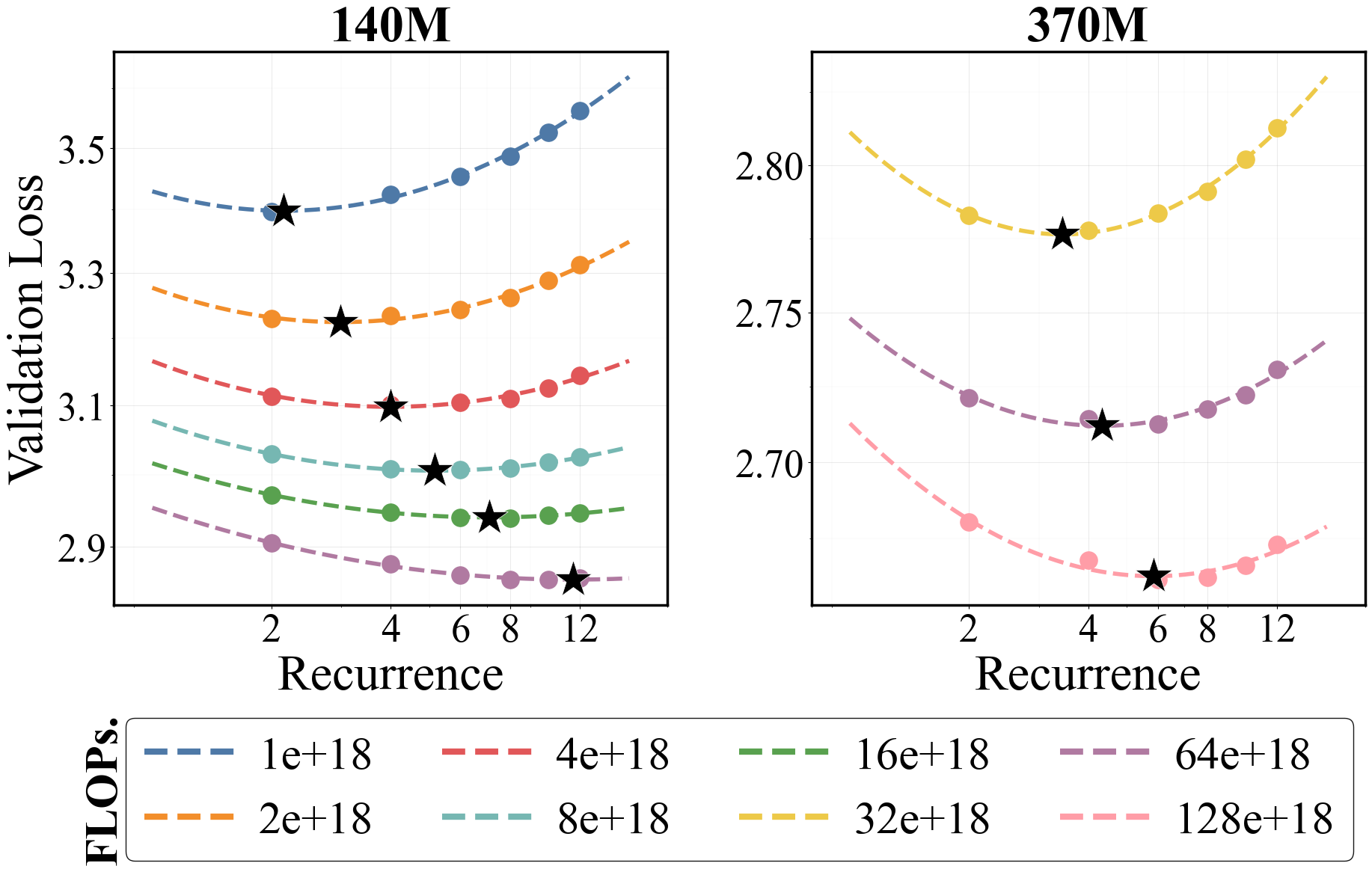
At two scales, we find that increasing the mean recurrence used in training, $\meanrecurrence$, while proportionally reducing tokens yields lower validation loss than training with low recurrence and more data. Even more interestingly, if we use a parabolic fit to extract the optimal $\meanrecurrence$ and token budget at each FLOP level, we find that both follow power laws with consistent exponents.
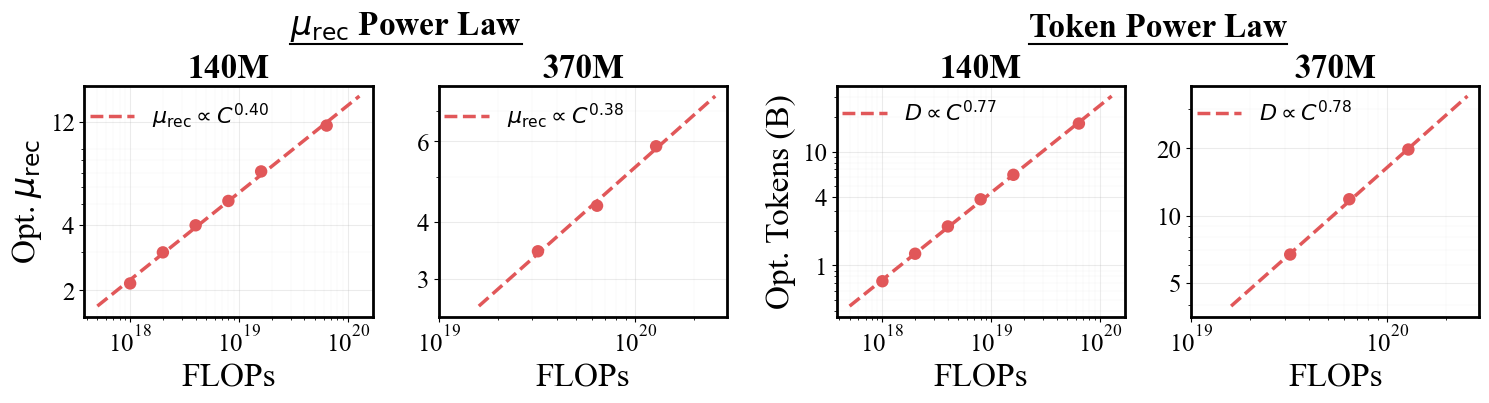
Alright, alright. But do we beat a fixed-depth model? Using our optimal recurrence scaling laws, we compare against fixed-depth Parcae models (i.e., those with $\meanrecurrence = 1$) and looped Parcae models that follow the optimal mean recurrence prediction from those scaling laws. We find that looping creates a stricter Pareto frontier for validation loss (figure below), which translates into better downstream quality (table below).
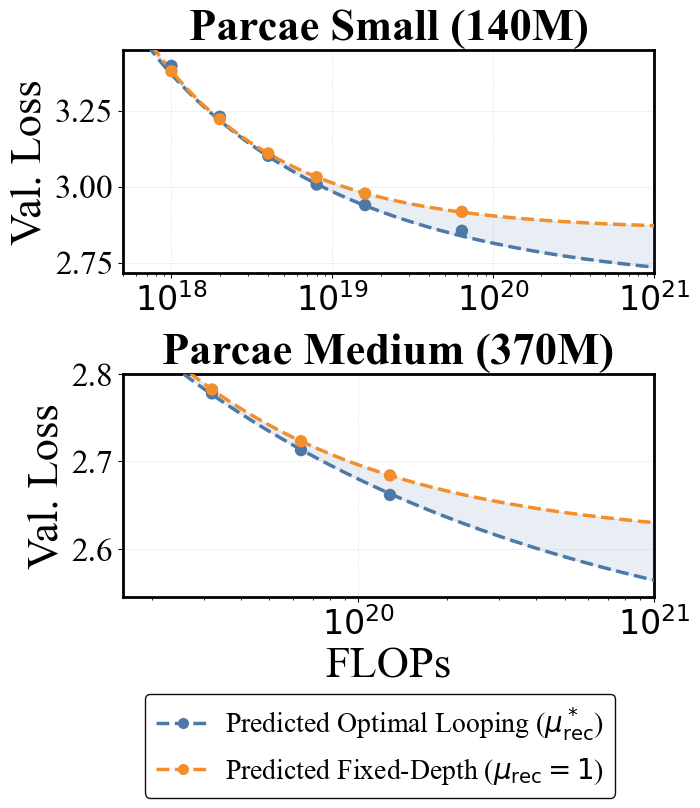
| FLOPs (x10^18) | Optimal Looping | Fixed-Depth |
|---|---|---|
| 1 | 7.6 | 7.9 |
| 4 | 11.2 | 10.7 |
| 16 | 14.6 | 13.0 |
| 64 | 16.2 | 15.0 |
| FLOPs (x10^18) | Optimal Looping | Fixed-Depth |
|---|---|---|
| 32 | 15.2 | 16.8 |
| 64 | 18.1 | 18.1 |
| 128 | 20.1 | 18.1 |
What’s next & trying out Parcae yourself.
We are super excited about how far we can push parameter efficiency. With the growing costs of memory overhead during inference, we think there is a lot to explore in parameter reuse methods such as layer looping. To help accelerate this process, we are releasing training code and Hugging Face models. We aren’t done either; we have tons of new ideas to push looped models further, so stay tuned for what comes next!
If you have any questions or want to work with us on what comes next for Parcae, please reach out to Hayden Prairie at hprairie@ucsd.edu.

The name PaRCae is a homage to the three roman fates: Nona (the Prelude block $\mathcal{P}$), who initializes the computational thread of life, Decima (the Recurrent block $\mathcal{R}$), who measures the thread and evolving through model depth, and Morta (the Coda block $\mathcal{C}$), who finalizes the sequences by cutting the thread to produce the final output.
Acknowledgements
We would like to thank Together AI for collaborating with us and providing compute for these experiments. We would also like to thank Austin Silveria and Jonah Yi for their helpful feedback on this blog post.
References
- Liu Yang, Kangwook Lee, Robert D. Nowak, and Dimitris Papailiopoulos. Looped Transformers Are Better at Learning Learning Algorithms. In The Twelfth International Conference on Learning Representations, 2024. ↩
- Jonas Geiping, Sean Michael McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling Up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach. In The Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025. ↩
- Ahmadreza Jeddi, Marco Ciccone, and Babak Taati. LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation. In The Fourteenth International Conference on Learning Representations, 2026. ↩
- Sean McLeish, Ang Li, John Kirchenbauer, Dayal Singh Kalra, Brian R. Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Jonas Geiping, Tom Goldstein, and Micah Goldblum. Teaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence. arXiv preprint arXiv:2511.07384, 2025. ↩